반응형
카프카(Kafka) 개념
pub-sub 모델의 메시지 큐
# 용도
- 메세지 처리
- 사용자의 웹 사이트 활동 추적 파이프라인
- 애플리케이션의 통계 집계
- 시간순으로 발생하는 이벤트를 저장해 필요한 곳으로 보냄
# Pub-Sub 모델
- 카프카는 pub-sub(발행/구독) 모델을 사용.
pub-sub은 메시지를 특정 수신자에게 직접적으로 보내주는 시스템이 아니다.
publisher는 메시지를 topic을 통해서 카테고리화 한다.
분류된 메시지를 받기를 원하는 receiver는 그 해당 topic을 구독(subscribe)함으로써 메시지를 읽어 올 수 있다. - 즉, publisher는 topic에 대한 정보만 알고 있고, 마찬가지로 subscriber도 topic만 바라본다. publisher 와 subscriber는 서로 모르는 상태다.
예제) 신문의 종류(topic)에 메시지를 쓴다. 우리는 그 해당 신문을 구독한다.
- 단점) 메시징 시스템이 중간에 있어서 전달속도가 빠르지 않음
이러한 단점을 극복하기 위해 메시지 전달의 신뢰성 관리를 producer & consumer 에게 넘기고, 교환기 기능을 컨슈머가 만들 수 있게 했다.
- zookeeper 가 kafka의 상태와 클러스터 관리를 한다.

# 카프카의 특징
- 메시징 큐의 일종
- Producer와 Consumer의 분리
- 말 그대로 분산형 스트리밍 플랫폼, LinkedIn에서 여러 구직 + 채용 정보들을 한곳에서 처리(발행/구독)할수 있는 플랫폼으로 개발이 시작
- 디스크에 메시지 저장
- 일반적인 메시징 시스템들은 Consumer가 메시지를 읽어가면 큐에서 메시지 삭제
- 보관 주기동안 디스크에 메시지 저장 (log.retention.hours(default : 168[7일])
(재시작으로 인한 메시지 유실 우려 감소) - 확장성
- 브로커 : 카프카 애플리케이션이 설치되어 있는 서버
- 3대의 브로커로 시작해 수십대의 브로커로 확장 가능
- 무중단 확장 가능
- 높은 성능
- 내부적으로 분산 처리, 배치 처리 기법 사용
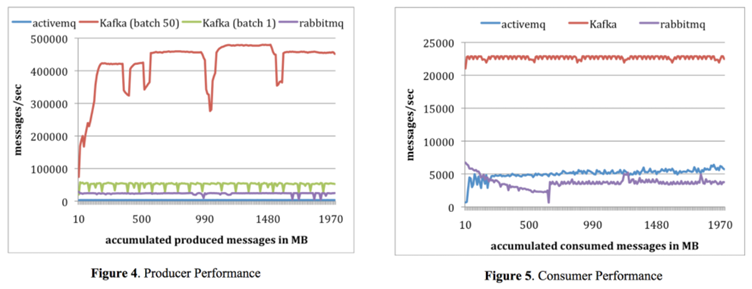
# 카프카 주요 개념
- producer : 메시지 생산(발행)자.
- consumer : 메시지 소비자
- consumer group : consumer 들끼리 메시지를 나눠서 가져간다.offset 을 공유하여 중복으로 가져가지 않는다.
- broker : 카프카 서버를 가리킴
- zookeeper : 카프카 서버 (+클러스터) 상태를 관리
- cluster : 브로커들의 묶음
- topic : 메시지 종류
- partitions : topic 이 나눠지는 단위
- Log : 1개의 메시지
- offset : 파티션 내에서 각 메시지가 가지는 unique id
# Topic과 partition
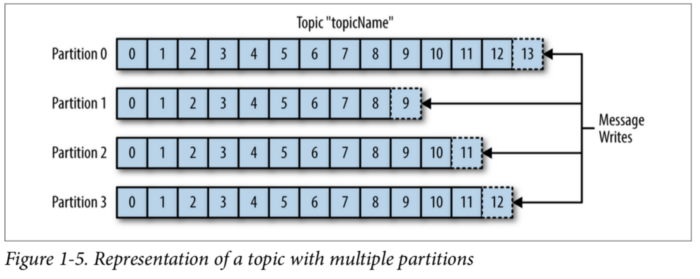
- topic은 여러개의 파티션으로 나눠 질 수 있다.
- 로그(Log) : 파티션내의 한 칸(데이터는 한칸의 로그에 순차적으로 append 된다.)
- 오프셋(offset) : 메시지의 상대적인 위치를 나타낸다. (like Index)
- ※ 주의 : 한번 늘린 파티션은 줄일 수 없기 때문에 파티션의 증가는 충분히 고려!
메시지가 Round-robin 방식으로 쓰여진다. ( 순차적으로 메시지가 쓰이지 않는다 )
# Producer, Consumer
- Producer : 메시지를 생산하는 주체, 메시지를 만들고 Topic에 메시지를 쓴다.
( 만약 여러개의 토픽에 여러개의 파티션을 나누고, 특정 메시지들을 분류해서 특정 파티션을 저장하고 싶다면, key 값을 통해 분류해서 넣을 수 있다. but 쉽지 않아 보인다. ) - Consumer : 메시지를 소비하는 주체, topic을 구독해 소비를 조절.
offset을 활용 마지막으로 읽었던 위치부터 다시 읽어들일 수 있다.
(fail-over에 대한 신뢰가 존재)
[틈새 지식] fail-over : 서버, 시스템, 네트워크 등의 이상이 발생한 경우, 시스템 대체 작동 또는 극복을 위해 예비 시스템으로 자동전환되는 기능. ( 수동 전환 : 스위치 오버 )
# Consumer Group

- Consumer Group : consumer들의 묶음
반드시 해당 topic의 파티션은 그 consumer group과 1 : n 매칭을 해야한다. - but 메시지가 쌓이는 속도보다 처리하는 속도가 빠른 경우
파티션 개수 => 컨슈머 개수도 not bad - consumer group 존재의 이유는 컨슈머 그룹은 하나의 topic에 대한 책임을 가지기 때문이다. (Rebalance : 그룹 내 어떤 컨슈머가 down 된 경우, 파티션 1에 대한 소비자가 사라지는 상황)
리벨런스의 경우 파티션 재조정을 통해 다른 컨슈머가 파티션1의 소비를 하게 된다. 그룹내에서 공유하는 offset 정보로 위치를 알고 소비하면 문제가 없다.

- 하얀색(consumer-01)
- 파티션 : 4개 & 컨슈머 : 3개, 컨슈머가 두개의 파티션을 담당하는 상황 - 주황색(consumer-02)
- 파티션 : 4개 & 컨슈머 : 5개, 담당이 없는 컨슈머가 생기는 상황 - 통상 컨슈머그룹의 consumer 개수와 partition 개수를 동일하게 유지한다.
# Broker, Zookeeper
- broker는 카프카의 서버를 칭한다. broker.id=1..n으로 함으로써 동일한 노드내에서 여러개의 broker서버를 띄울 수도 있다.
- zookeeper는 이러한 분산 메세지 큐의 정보를 관리해 주는 역할을 한다. kafka를 띄우기 위해서는 zookeeper가 반드시 실행되어야 한다.
# Replication
local에 broker3대를 띄우고(replica-factor=3)로 복제되는 경우를 살펴보자.
복제는 수평적으로 스케일 아웃이다. broker 3대에서 하나의 서버만 leader가 되고 나머지 둘은 follower 가 된다. producer가 메세지를 쓰고, consumer가 메세지를 읽는 건 오로지 leader가 전적으로 역할을 담당한다.
# 파이프 라인 사례
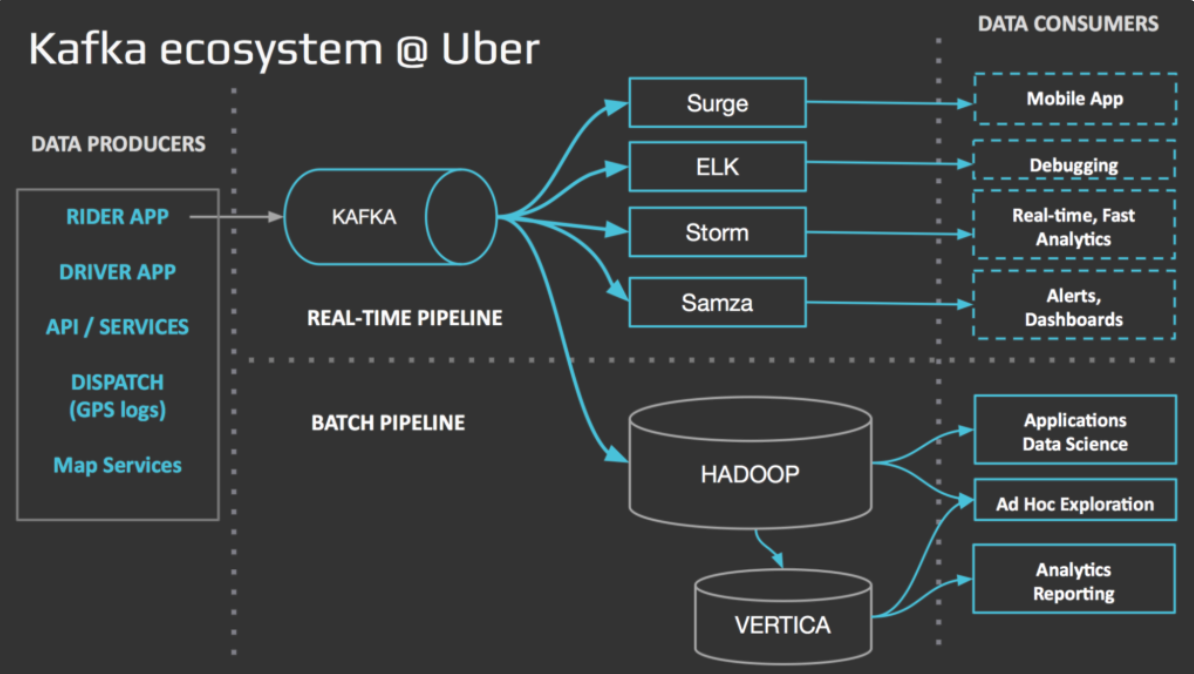

[참고 URL] 감사합니다.
- https://taetaetae.github.io/2017/11/02/what-is-kafka/
- https://zzsza.github.io/data/2018/06/15/apache-kafka-intro/
- https://han.gl/i58Jw
- https://semtax.tistory.com/83( Springboot - kafka)
- https://han.gl/LOl1q ( Springboot - kafka)
반응형
'KAFKA > 개념 정리' 카테고리의 다른 글
| ELR(Eligible Leader Replicas) — ISR/HW 메커니즘의 구조적 한계와 해결 (0) | 2026.04.16 |
|---|---|
| Kafka의 메시지 복제를 이해하는 세 가지 키워드 — LEO, HW, acks (0) | 2026.04.15 |
| [KAFKA] APACHE KAFKA 기초 (0) | 2021.04.13 |
| [KAFKA] APACHE KAFKA 개요 (0) | 2021.04.13 |

